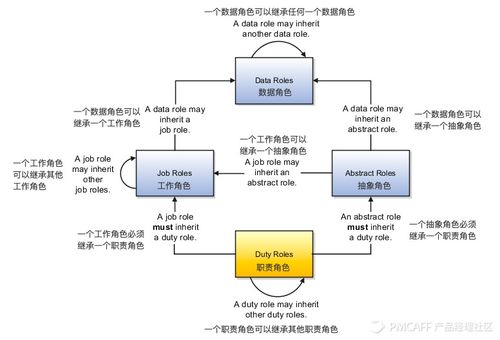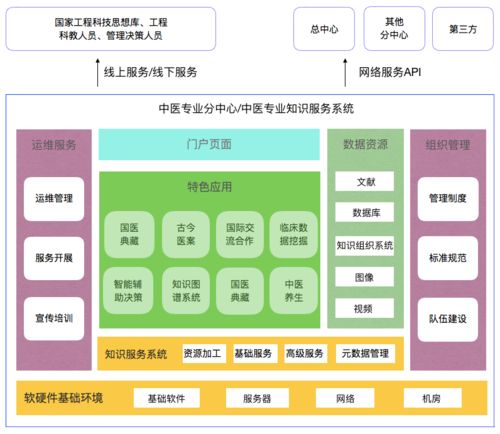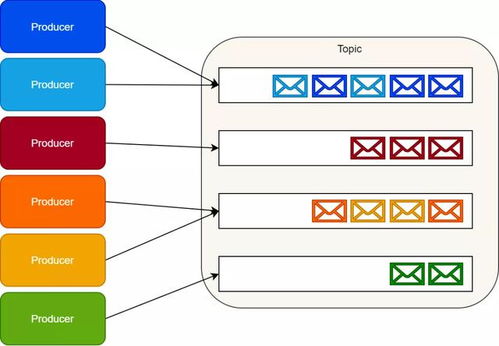
在分布式系统的世界里,消息队列如同信息高速公路的交通枢纽,承载着系统间海量数据的流转。RabbitMQ与Kafka,两位消息中间件的“神仙”,在信息系统运行维护服务的战场上屡屡交锋。本文将以七轮比拼的形式,剖析二者特性,看谁能在企业级运维中加冕为王。
第一战:架构哲学
RabbitMQ遵循AMQP协议,采用经典的Broker中心化架构,以消息代理为核心,确保每条消息的精准投递。它像一位严谨的邮差,注重消息的确认与路由。Kafka则奉行分布式提交日志理念,以分区、副本机制构建高吞吐的流数据平台,更像一个高速传送带,追求海量数据的持续流动。在需要严格顺序与事务支持的运维场景中,RabbitMQ的确定性更受青睐;而在日志聚合、实时流处理中,Kafka的吞吐能力一骑绝尘。
第二战:性能吞吐
Kafka为吞吐而生,单机即可轻松达到每秒数十万条消息,线性扩展能力极强,适合大数据量、高并发的场景,如监控日志的实时采集。RabbitMQ在中小规模吞吐下表现稳定,但在极高负载时需精细调优。对于运维系统而言,若日均处理亿级事件,Kafka常是首选;若更注重消息的复杂路由与即时性,RabbitMQ的延迟往往更低。
第三战:消息可靠性
RabbitMQ提供从生产者确认、持久化到消费者确认的完整可靠性保障,支持死信队列,适合对消息零丢失要求极高的金融、订单系统运维。Kafka通过副本机制与ISR集合保证数据不丢失,但消费者需自行处理重复消费等问题。在运维告警、配置下发等不容有失的场景,RabbitMQ的“稳妥”特质更契合;对于日志类可容忍极小概率丢失的数据,Kafka的权衡更为高效。
第四战:扩展与集群
Kafka原生为分布式设计,扩展只需增加Broker,分区自动重平衡,运维相对简单。RabbitMQ集群虽成熟,但镜像队列等配置需人工介入,跨机房同步更复杂。在需要弹性伸缩的云原生运维环境中,Kafka的扩展性略胜一筹;而在中小规模固定集群中,RabbitMQ的稳定集群亦久经考验。
第五战:生态与集成
RabbitMQ插件生态丰富,支持MQTT、STOMP等多协议,易于与传统系统集成。Kafka依托Connect、Streams等组件,构建了完整的流处理生态,适合构建数据管道。运维服务中,若需连接多样异构设备(如IoT传感器),RabbitMQ的多协议支持更具优势;若目标是构建统一的运维数据平台,Kafka的流式生态更能支撑未来演进。
第六战:运维复杂度
RabbitMQ管理界面友好,监控指标直观,故障排查相对容易。Kafka运维门槛较高,需关注分区、副本、控制器等多层状态,但成熟的管理工具(如CMAK)已逐渐补齐短板。对于运维团队而言,RabbitMQ更易“上手即用”;而拥有专职中间件团队的场景,Kafka的深度可控性反成优点。
第七战:场景适配度
在信息系统运行维护服务中,RabbitMQ擅长处理任务分发、RPC调用、延迟队列等典型应用运维需求,其灵活性在微服务间通信中表现卓越。Kafka则主宰日志收集、指标聚合、事件溯源等可观测性领域,为运维分析提供实时数据流。二者并非简单替代,而是互补共存:许多企业以Kafka承载数据洪流,用RabbitMQ处理核心事务消息。
王者之争,实为场景之选
RabbitMQ与Kafka的“七战”,实则是不同设计哲学的碰撞。RabbitMQ以消息为中心,精于控制与可靠;Kafka以日志为基,擅长吞吐与流式。在信息系统运维的宏大图景中,没有绝对的王者,只有最适合的利器。明智的架构师,往往根据业务场景混合部署——让Kafka成为运维数据的“动脉”,承载监控与日志的奔流;让RabbitMQ作为“毛细血管”,确保关键指令的精准送达。二者协同,方能构建起既稳健又高效的数字世界运维基石。